This page provides more information on the Longtermism Fund’s ($110,000) grant to support Professor Martin Wattenberg and Professor Fernanda Viégas to develop their AI interpretability work at Harvard University.
What will this grant fund?
This grant will fund research into methods for looking at the inner workings of an AI system and inferring from this why the AI system produces the results it does. (This is often called mechanistic interpretability.)
Currently, we have almost no ability to understand why the most powerful systems make the decisions they make. They are mostly a “black box”. For example:
- A foundational project called “Toy Models of Superposition” (which Prof. Wattenberg was a key contributor to) investigates how a single neuron of a neural network commonly represents multiple concepts.
- Substantially as a result of this, in OpenAI’s work on what GPT-2 neurons correspond to, the organisation only found reasonably clear explanations for what ~1,000 of the 307,200 neurons (0.3%) represent.
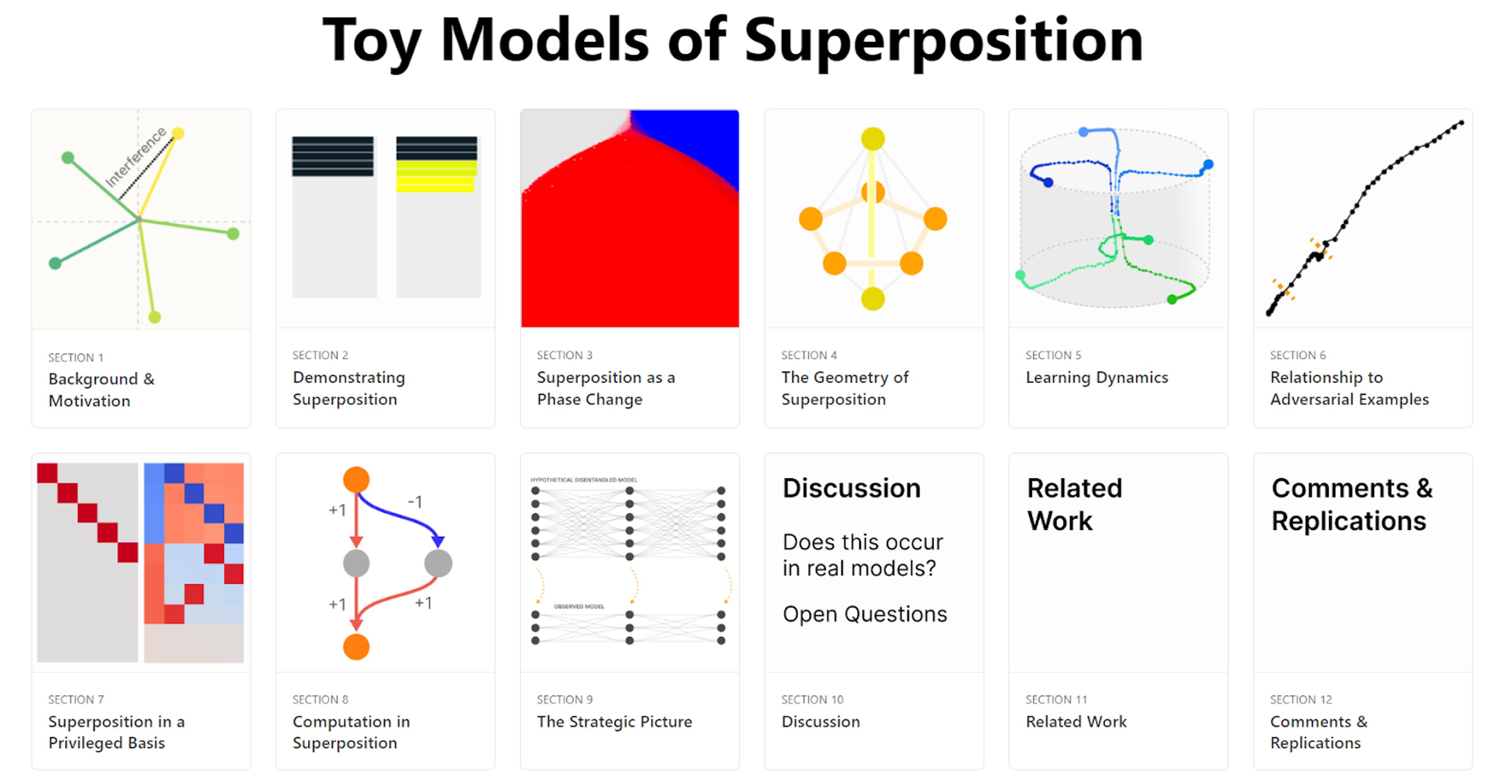
This grant supports work to change this. Specifically, it will support Prof. Wattenberg and Prof. Viégas to:
- Research identifying how the inner workings of neural networks drive their outputs (primarily identifying models of the world inside neural networks, such as a representation of the board state in the game Othello); and
- Build tools to help them and others investigate neural networks (such as their work on visualising transformer attention — pictured below).
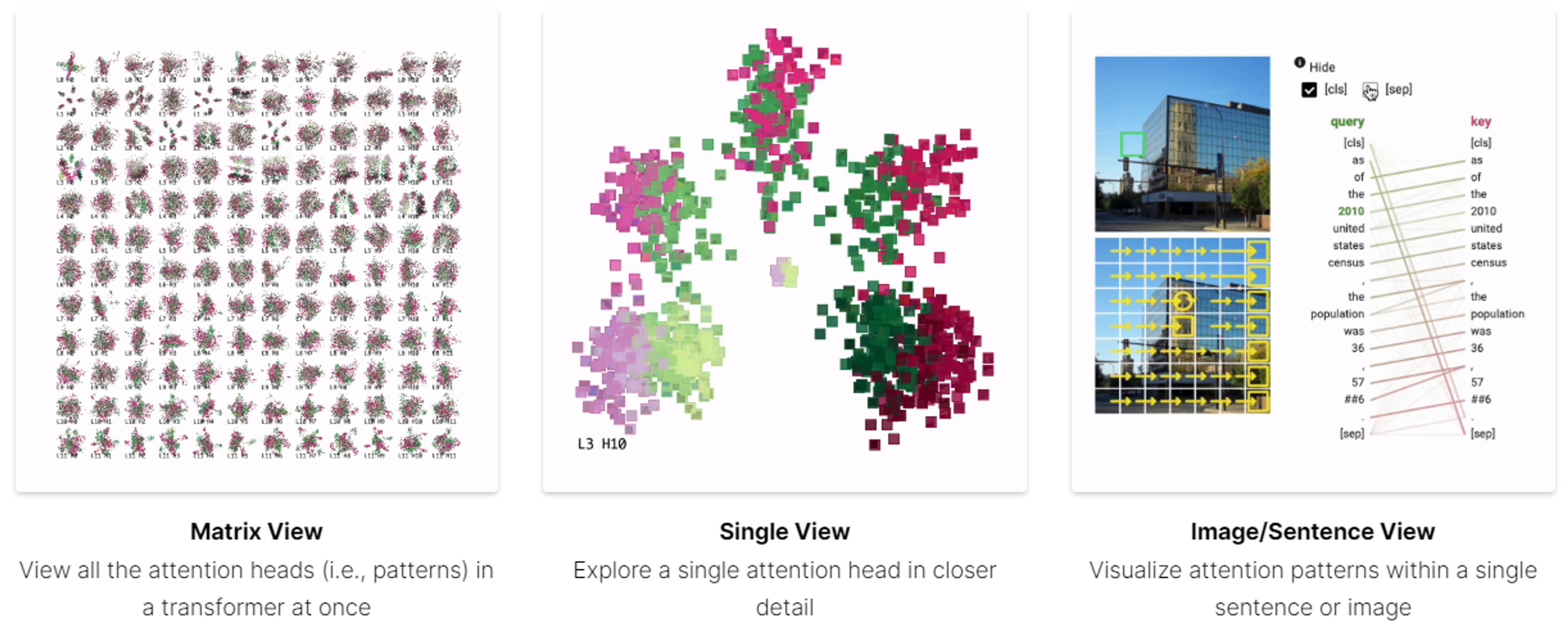
Concretely, most of this funding will help them to (A) set up a compute cluster needed to work on these projects at the cutting edge of AI, and (B) hire graduate students or possibly postdoctoral fellows.
One of Prof. Wattenberg and Prof. Viégas’ dreams is to make possible dashboards that display what an AI system believes about its user and about itself. This is very ambitious, but would have a wide range of benefits. Notably for the Fund’s goals, progress toward this goal could help AI developers to detect unwanted processes within AI systems, such as deception. Perhaps it could even lead to a more reliable understanding of what goals systems have learned. The feasibility of this type of progress remains to be seen.
What evidence is there of the grant's effectiveness?1.
Longview Philanthropy — one of Giving What We Can’s trusted evaluators — recommended this grant after investigating its strength compared to other projects. This investigation involved:
- Assessing Martin Wattenberg’s and Fernanda Viégas’ track record in the area, including by consulting other researchers for their views on the quality and potential impact of their work. (See examples of past work linked above.)
- Meeting with them to discuss how they would plan to use the funding and considering how likely these plans are to advance the kind of AI interpretability that might reduce catastrophic and existential risks from AI.
At Giving What We Can, we focus on the effectiveness of an organisation's work -- what the organisation is actually doing and whether their programs are making a big difference. Some others in the charity recommendation space focus instead on the ratio of admin costs to program spending, part of what we’ve termed the “overhead myth.” See why overhead isn’t the full story and learn more about our approach to charity evaluation.